Google vs. könyvtári katalógus
Keresőmotorok
A népszerű webkeresők ma már az információkutatás alapvető eszközeit jelentik. Teljes természetességgel fordulunk hozzájuk - legyen szó bármilyen információról - s élvezzük a könnyen, gyorsan hozzáférhető információelérés előnyeit.
Ennek egyik negatív mellékhatása azonban, hogy azoknak az információknak, melyek a Google, a Yahoo vagy a Bing univerzumán kívül esnek (ezt hívjuk "láthatatlan web”-nek) sokszor még a létezéséről sem tudunk, vagy "csak” figyelmen kívül hagyjuk őket.
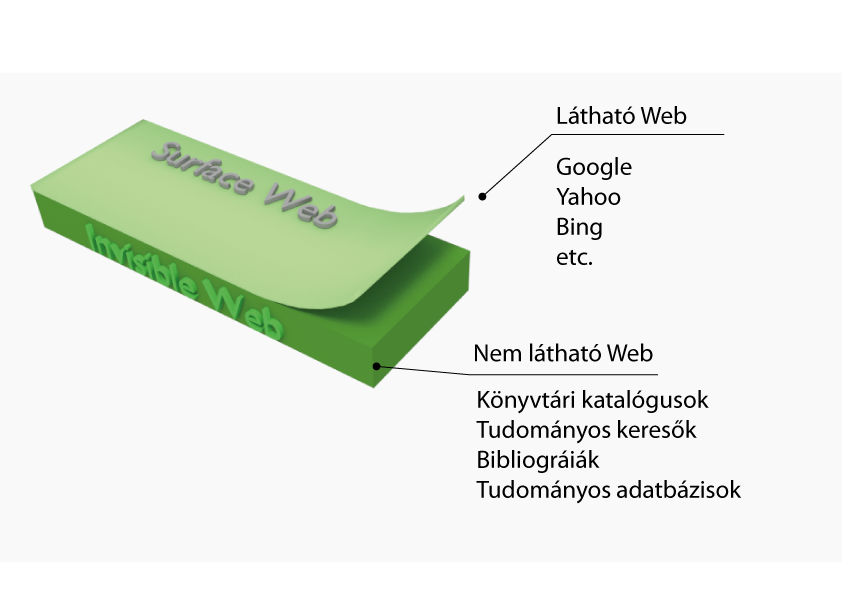
Számos nyilvánvaló előnyük mellett tehát érdemes figyelembe venni, hogy az ilyen keresők keresők kizárólagos hasznával:
- csak a látható webet böngésszük, vagyis kimaradhatnak érdeklődésünk szempontjából fontos, de pl. előfizetéshez kötött, vagy speciális gyűjteményekben található források
- számos nem releváns találatot kapunk, melyek egy része "csak" felesleges, más része viszont kifejezetten félrevezető lehet
- az interneten található tartalmak meghatározó része "caveat emptor”, vagyis olyan tartalom, amelynek létrejöttét elsősorban a potenciális felhasználók elvárásai határozzák meg, és nem feltétlenül a tudományos igényesség, adatpontosság vagy az objektív megközelítés.
Az adatbázisok
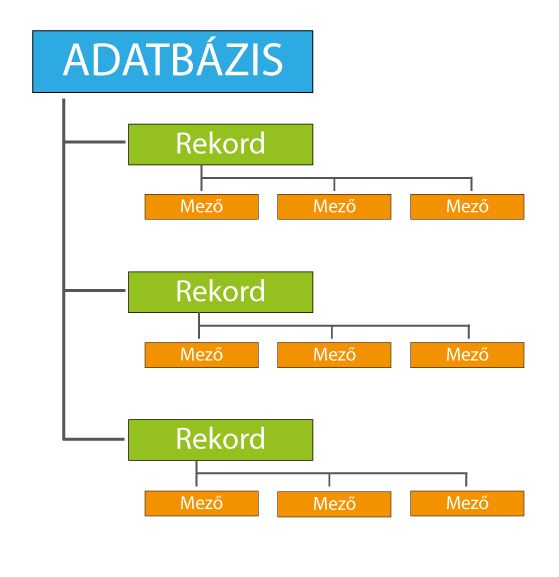
Az adatbázis azonos minőségű (jellemzőjű), többnyire strukturált adatok összessége, amelyet egy tárolására, lekérdezésére és szerkesztésére alkalmas szoftver kezel.
Az adatbázisokra érdemes úgy gondolni, mint egyfajta tartályra, amelyben külnönböző adatok (információk) vannak.
Az adatbázis rekordokból épül fel. A rekordok mezőkből (field) állnak, ahol minden mezőnek neve és típusa van. Az azonos mezőtípusok adataiból tömbök képződnek, a tömbök elemeire indexekkel hivatkozhatunk.
最終更新日時: 2019年 02月 25日(Monday) 14:30